
本文源码基于 React 16.8.6 (March 27, 2019),仅记录一些个人阅读源码的分享与体会。
- React 源码 Scheduler(一)浏览器的调度
- React 源码 Scheduler (二) React 的调度流程
- React 源码 Scheduler (三) React 的调度算法实现
前言
在上一节中,笔者介绍了浏览器中调度算法的种类,并基于此实现了一个简单的时间分片调度。
React 的调度流程借鉴了浏览器中 requestIdleCallback 的模式,实现了时间片的分割与超时任务的调度管理功能。
同时,作为跨平台框架的 React,将各个平台功能的底层实现抽象出一层 HostConfig 的 API 层,如此一来既保证了各平台 API 接口的统一性和健壮性,也便于构建 mock api 以供测试,值得我们借鉴学习。
在本节中,我们将一起深入 React 源码中,探究其内部调度的实现。
Scheduler
React 调度算法的源码位于 packages/scheduler/src/Scheduler.js 文件。在阅读源码之前,为了让大家对于该算法有一个整体的认识,笔者制作了如下类图:

抛开函数部分暂不谈,Scheduler 数据成员主要分为任务优先级设定,不同优先级任务超时时间设定和一些记录当前任务状态的私有成员变量。
在 React 中,任务优先级由高至低可依次分为 Immediate,UserBlocking,Normal,Low,Idle。同时每种任务也有着各自的超时时间,避免任务陷入饿死状态。该任务的分类就是 React 中基于优先级的时间分片调度算法基础。
调度的执行过程
跟随源码,我们找到了调度算法的入口 unstable_scheduleCallback。外部环境通过该函数的调用添加任务至优先级队列,正式打开调度流程的大门。
scheduleCallback
1 | function unstable_scheduleCallback(priorityLevel, callback, deprecated_options) { |
在 scheduleCallback 函数中,运用了一个双向循环队列 firstCallbackNode 作为调度节点的存储。函数一共做了三件事。
- 计算超时时间
expirationTime - 建立一个
callBackNode,按照超时时间从小到达的顺序插入队列 - 尝试通过
scheduleHostCallbackIfNeeded进行调度
超时时间的设置,保证了任务在最坏的情况下仍旧能被最终执行,firstCallbackNode 的队列记录了每一个最小化的原子任务(即该任务无法再进行中断切换),以便在调度时执行。接下来让我们走进 scheduleHostCallbackIfNeeded,
scheduleHostCallbackIfNeeded
1 | function scheduleHostCallbackIfNeeded() { |
scheduleHostCallbackIfNeeded 函数做的事情也很简单,在任务队列建立好之后。如果当前任务正在执行中,则直接退出调度,防止多次重复进入调度造成的性能损失。同时,如果任务正在调度但尚未执行,则说明新进任务优先级更高,中断原先任务调度执行新任务。虽然任务的回调函数都是 flushWork, 但优先级更高的任务拥有更小的 expirationTime,因此能保证任务更快执行。
flushWork
经过了上述两步调度预处理后,我们进入了真正执行调度任务的地方。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38function flushWork(didUserCallbackTimeout) {
//...
isHostCallbackScheduled = false;
isPerformingWork = true;
const previousDidTimeout = currentHostCallbackDidTimeout;
currentHostCallbackDidTimeout = didUserCallbackTimeout;
try {
if (didUserCallbackTimeout) {
// 调度超时,执行全部超时任务
while (firstCallbackNode !== null) {
var currentTime = getCurrentTime();
if (firstCallbackNode.expirationTime <= currentTime) {
do {
flushFirstCallback();
} while (
firstCallbackNode !== null &&
firstCallbackNode.expirationTime <= currentTime // 如果任务超时
);
continue;
}
break;
}
} else {
// 调度未超时,则执行任务直到超时挂起
if (firstCallbackNode !== null) {
do {
flushFirstCallback();
} while (firstCallbackNode !== null && !shouldYieldToHost());
}
}
} finally {
isPerformingWork = false;
currentHostCallbackDidTimeout = previousDidTimeout;
// 检查是否有遗留任务未执行
scheduleHostCallbackIfNeeded();
}
}
正如 requestIdleCallback 的方案,在执行任务时,函数能通过 didUserCallbackTimeout 变量识别调度任务是否已超时,同时能通过 shouldYieldToHost 函数获取到当前状态,即是否仍有剩余时间进行下一项任务的执行。
若进入函数时调度任务已经超时,则说明这个任务已经等太久了,再不让执行就要饿死了!因此,便获得了在不打断的情况下执行所有已超时的任务的权限。若当前调度尚未超时,则在规定的时效内,尽可能多的执行任务。当该次调度执行完毕(不管是任务执行完或者因为中断暂停执行),在任务执行完毕后重新执行 scheduleHostCallbackIfNeeded 为下一次的任务调度做准备。
flushFirstCallback
该函数是回调任务最终执行之处,做的事情归纳起来也就三点。
- 从队列中获取并移除
firstCallbackNode - 进行
firstCallbackNode回调函数的执行 - 若回调函数结果仍是一个函数,则构建并加入队列
1 | function flushFirstCallback() { |
总结
至此,React 的基础调度流程便算是走了一遍,让我们最后通过一个流程图对整个流程做一个梳理。
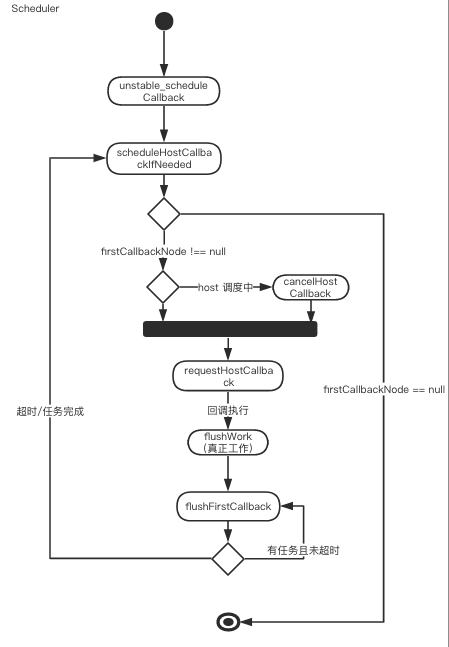
每一个调度流程,都由 scheduleCallback 函数为入口,经由检查器 scheduleHostCallbackIfNeeded 将任务标记为调度状态,在 flushWork 中循环调用执行任务,最后在任务执行完毕 firstCallbackNode 为空时,由 scheduleHostCallbackIfNeeded 函数确认任务执行完毕,结束该调度流程。
在阅读过程中,或许有一些小伙伴发现,诸如 requestHostCallback,cancelHostCallback 等函数我们并没有介绍内部实现。这些便是我们开头所说的 React 基于不同平台做的抽象层接口。在下一篇也是最后一篇中,我们将走进这些函数的背后,学习在浏览器的平台上 React 是如何模拟时间分片的。